
Nimit Kalra CV
Hello! I'm a Researcher with Micah Goldblum at Columbia working on LLM reasoning. I was a researcher at Haize Labs, working on red-teaming, adversarial search, and post-training custom evaluator models. Before that, I spent three years working in quant finance. I am applying for PhD positions starting Fall 2026.
During my undergrad years, I focused on computer vision and was fortunate to be advised by Philipp Krähenbühl on domain adaptation for real-world visuomotor navigation and robotics tasks. I grew up near Dallas and spent most of my childhood staying up too late hacking around with iOS jailbreaking/Cydia and Minecraft mods. Amidst the urban sprawl, I found escape in the mountains.
Writing
Bootstrapping Reasoning in LLMs, Aug 2025 |
Projects
| [July 2025] | [code] | spoken: Inference Wrapper for Speech Foundation Models |
| [May 2025] | [code] | j1-micro: Tiny DeepSeek Generative Reward Models |
| [Apr 2025] | [demo] | EvalsEvalsEvals: Automated Rubric Creation for LLM Evals |
| [Jan 2021] | [code] | Map-View Point Transformers for Autonomous Navigation |
| (see more) ⤵ | ||
| [Oct 2020] | [code] | Domain Adaptation for Indoor PointGoal Navigation |
| [May 2020] | [report] | Domain Adaptation via Noisy Label Multi-Task Distillation |
| [May 2020] | [report] | A Bayesian Network Model for Sampling Dockless Scooter Traffic |
| [Oct 2020] | [report] | High-Dimensional SVMs with Fast Random Kernelized Features |
| [Mar 2017] | [report] | Composition of Real Flows |
Publications/Preprints
|
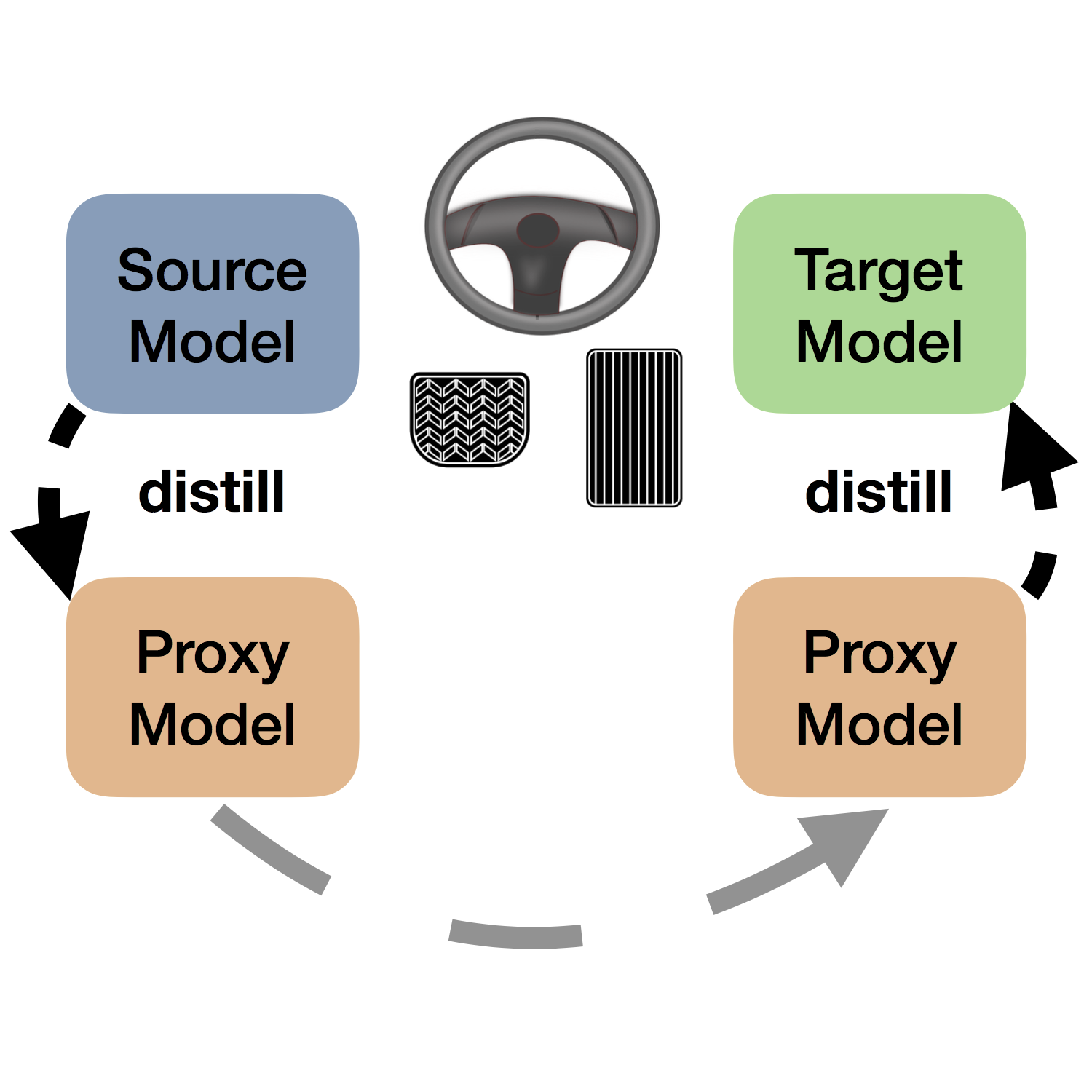
Closing the Train-Test Gap in World Models for Gradient-Based Planning Although world models are trained on next-state prediction, at test-time we use them to estimate actions via gradient descent. Our adversarial and online training methods close this train–test gap, enabling gradient-based planning to surpass costly search methods (e.g., CEM) on robotic manipulation tasks. |
|
|
Verdict: A Library for Compound LLM Judge Systems Open-source library for scaling test-time compute via graphs of chained prompted evaluators. We achieve SOTA/near-SOTA performance on a wide variety of challenging automated evaluation tasks without additional training or resorting to specification/prompt overfitting. |
|
|
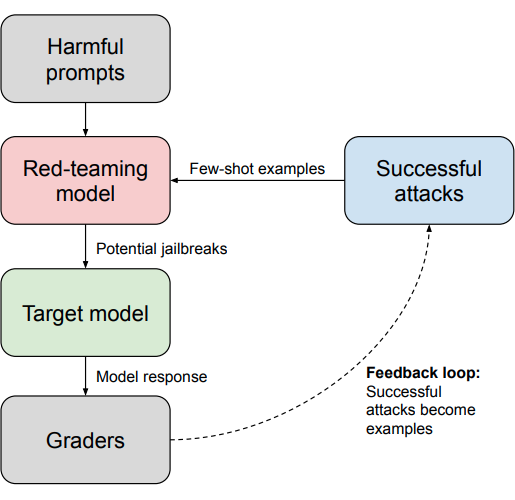
Constitutional Classifiers: Defending Against Universal Jailbreaks Synthetic data recipe for training output classifiers with streaming prediction to flag harmful content according to an explicit constitution. Focus on adversarial data augmentation and red-teaming. |
|
|
Domain Adaptation Through Task Distillation, ECCV 2020 We leverage dense vision labels (e.g., segmentation masks, which are freely available in simulators) to transfer navigation policies across visually-diverse domains (maze navigation → autonomous driving). By training a policy that operates on labels, we can obtain action supervision in a new domain and distill an end-to-end visuomotor policy. |

Adventures
I enjoy a good road trip.
Hiking
Emory Peak, Big Bend National Park
Cascade Mountain, Adirondack High Peak Wilderness
Mt. Kosciuszko, Kosciuszko National Park
Chasm Lake via Long Peak's Trail, Rocky Mountain National Park
Rim-to-Rim, Grand Canyon National Park
Eiffel Lake / Parker Ridge, Banff National Park
Corkscrew Peak, Death Valley National Park
Mt. Charleston, Red Rock Canyon National Conservation Area
Contact
I love meeting new people. Reach me at nimit@utexas.edu or schedule a quick chat.